Plus rapides, moins chers, plus contrôlables – et toujours performants : les Small Language Models conquièrent l’entreprise.
Pendant que le monde se focalise sur GPT-5 et des modèles toujours plus grands, quelque chose de passionnant se passe en coulisses : les Small Language Models (SLMs) évoluent rapidement et deviennent une vraie alternative pour les applications d’entreprise. Dans notre dernier webinaire, nous avons montré pourquoi – avec une démonstration live de nos propres modèles fine-tunés.
Le problème avec les grands modèles
80-95% des projets IA en entreprise échouent. Un chiffre qui donne à réfléchir et qui fait régulièrement la une. Mais pourquoi ?
Une raison majeure : les grands modèles de langage comme ChatGPT ou Claude posent souvent problème en entreprise. OpenAI a récemment désactivé toutes les anciennes versions de ses modèles lors du lancement de GPT-5 – un cauchemar pour toute DSI avec des processus en production. Ajoutez les préoccupations de confidentialité, le comportement imprévisible et la dépendance aux services cloud américains.
Petits mais costauds : Les avantages des SLMs
Les Small Language Models (typiquement 1-20 milliards de paramètres) offrent des avantages concrets :
⚡ Vitesse : Des réponses en millisecondes au lieu de plusieurs secondes d’attente. Une fois qu’on a goûté à la réactivité d’un SLM local, impossible de revenir en arrière.
🔒 Confidentialité : Fonctionne sur vos propres serveurs, pas besoin d’internet, aucune donnée ne quitte vos locaux. Idéal pour les données sensibles.
🎯 Contrôle : Pas de mises à jour surprises du modèle, pas de changements de comportement soudains. Le modèle fait exactement ce qu’il doit faire.
💰 Coût : Nettement moins cher à exploiter que les appels API aux grands fournisseurs.
🔧 Personnalisation : Grâce au fine-tuning, les SLMs peuvent être entraînés précisément pour des tâches spécifiques – avec un effort raisonnable.
Le secret : Le fine-tuning LoRA
Le game-changer s’appelle LoRA (Low-Rank Adaptation). Cette technique permet de personnaliser des modèles avec étonnamment peu de données (à partir d’environ 100 exemples) et de puissance de calcul. Le principe : on entraîne uniquement un petit « adaptateur » qui se superpose aux poids du modèle – pas besoin de réentraîner tout le modèle.
Le résultat ? Un modèle qui non seulement donne les bonnes réponses, mais répond aussi avec le bon style. Tous ceux qui ont essayé de faire donner des réponses plus courtes à ChatGPT ou d’éviter certains formatages par le seul prompt savent à quel point c’est difficile. Avec le fine-tuning, ça marche de façon fiable.
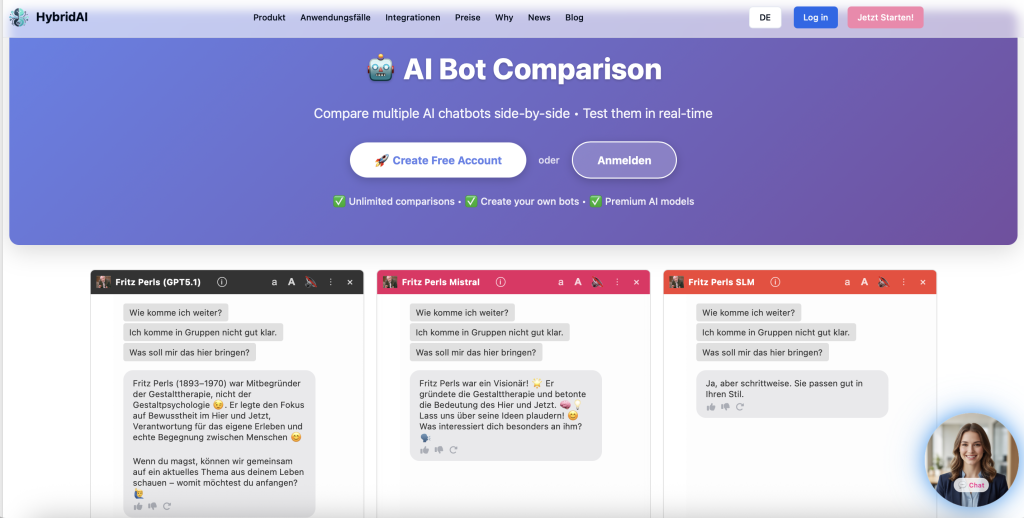
Démo live : Nos propres SLMs
Dans le webinaire, nous avons présenté trois modèles fine-tunés, tous basés sur le LFM-2 de LiquidAI avec seulement 1,4 milliard de paramètres :
- Modèle allemand général : Des réponses solides aux questions quotidiennes et techniques
- Bot thérapie Fritz Perls : Un modèle qui imite parfaitement le style de conversation confrontationnel du thérapeute Gestalt Fritz Perls
- Modèle d’association études de marché : Analyse les associations de marque implicites dans le style d’études de marché professionnelles
La réactivité est impressionnante – les réponses arrivent pratiquement instantanément. Et le meilleur : tout tourne sur nos propres serveurs européens.
L’avenir : L’hybride est roi
Notre vision chez HybridAI : c’est la combinaison qui compte. Petits modèles fine-tunés pour les tâches routinières, grands modèles pour les requêtes complexes – le tout orchestré par une couche de contrôle intelligente qui reconnaît quel modèle convient à chaque situation.
Cela donne aux entreprises le meilleur des deux mondes : des réponses rapides, contrôlables et conformes à la confidentialité pour 80% des requêtes – et la puissance des grands modèles quand c’est vraiment nécessaire.
Envie d’essayer ?
Nous mettons notre démo SLM à disposition du public. Testez vous-même les performances des petits modèles – et contactez-nous si vous souhaitez discuter de modèles fine-tunés personnalisés pour vos cas d’usage.