Soyons honnêtes : votre entreprise dispose-t-elle de toutes les informations pertinentes en un clic ? Ou sont-elles également coincées chez vous dans divers silos de données, largement déconnectés – l’ERP ici, le CRM là, plus des fichiers Excel sur des disques personnels et des documents stratégiques quelque part dans le cloud ?
Si vous hochez la tête en ce moment, vous êtes en bonne compagnie. Je parle régulièrement avec des dirigeants et des responsables financiers, et le constat est presque toujours le même : les données seraient là. Mais les rassembler pour répondre à une question précise prend des jours – si tant est que quelqu’un puisse le faire.
Pourquoi cela devient un problème maintenant
L’époque où les entreprises pouvaient compter sur des marchés stables et des évolutions prévisibles est révolue. Inflation, tensions géopolitiques, chaînes d’approvisionnement perturbées, marché du travail en mutation – tout cela impose une nouvelle discipline : les décisions doivent non seulement être bonnes, elles doivent être bonnes rapidement.
La Business Intelligence classique a une réponse éprouvée : tableaux de bord, KPIs, rapports mensuels. Mais soyons francs – ces outils atteignent leurs limites dès que les questions deviennent plus complexes. Qu’advient-il de notre marge si nous changeons de fournisseur ? Comment une augmentation de prix affecte-t-elle les différents segments de clientèle ? Quels scénarios se dessinent si l’euro continue de baisser ?
De telles questions nécessitent plus que des graphiques statiques. Elles nécessitent une vraie conversation avec vos propres données.
La tentation : un sparring-partner IA pour vos décisions
C’est exactement là que l’IA générative devient vraiment passionnante. L’idée est séduisante : un assistant intelligent qui connaît les chiffres de votre entreprise, comprend les connexions et vous permet d’explorer des options stratégiques – à tout moment, sans coordination d’agenda, sans que quelqu’un doive d’abord construire une analyse.
« Comment nos 10 meilleurs clients ont-ils évolué au dernier trimestre ? » « Et si nous réduisions le portefeuille de produits de 20 % ? » « Compare notre structure de coûts avec l’année dernière et montre-moi les plus grands écarts. »
Un tel dialogue démocratiserait la Business Intelligence. Plus seulement le contrôleur de gestion avec son expertise Excel aurait accès aux insights – chaque décideur pourrait interroger les données lui-même. Je trouve toujours cette idée fascinante.
Le problème : quand l’IA hallucine, ça coûte très cher
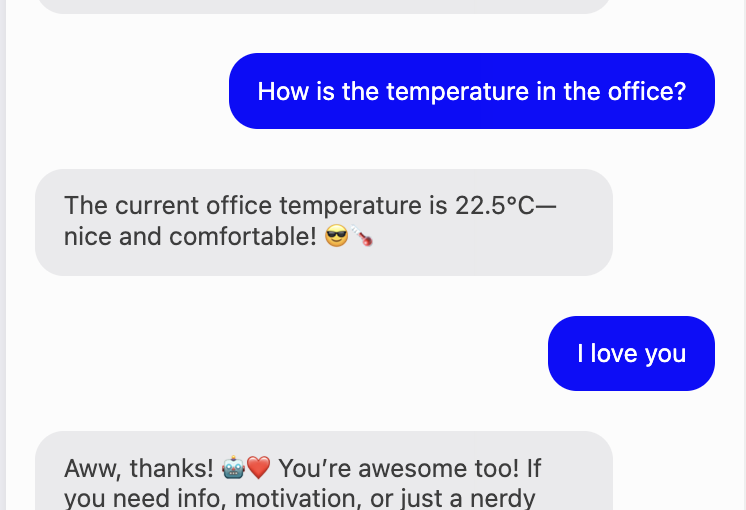
Mais – et c’est un grand mais – voilà le hic. Les grands modèles de langage sont impressionnants pour générer des réponses qui sonnent plausibles. Ils sont nettement moins fiables pour fournir des réponses factuellement correctes. Surtout quand il s’agit de chiffres concrets.
Une IA qui se trompe de date dans un texte créatif ? Agaçant, mais gérable. Une IA qui invente un chiffre d’affaires ou calcule mal une marge lors d’une décision commerciale ? Ça peut faire vraiment mal. Le danger se multiplie parce que les réponses sont si diablement convaincantes. Nous, les humains, avons tendance à faire confiance à une affirmation présentée avec assurance – même quand elle provient d’un modèle linguistique statistique.
Je le dis d’expérience : une intégration naïve de ChatGPT avec les données de l’entreprise est un risque, pas un progrès. Ceux qui voient les choses autrement ont soit eu de la chance, soit ne s’en sont pas encore rendu compte.
Le défi technique : connecter trois mondes
La solution réside dans une architecture bien pensée qui rassemble intelligemment trois sources de données différentes :
Données structurées via SQL : Les faits bruts – chiffres d’affaires, coûts, quantités, historiques clients – résident généralement dans des bases de données relationnelles. Ici, l’IA ne doit pas deviner mais interroger précisément. Le système doit générer des requêtes SQL, les exécuter et interpréter correctement les résultats. Aucune place pour la créativité.
Données non structurées via RAG : Au-delà des chiffres, il y a le contexte – documents stratégiques, analyses de marché, directives internes, comptes rendus. Ces documents peuvent être exploités via le Retrieval Augmented Generation : le système recherche des passages de texte pertinents et les fournit au modèle de langage comme contexte.
Le savoir général du modèle : Enfin, le LLM apporte ses propres connaissances – sur les secteurs, les relations économiques, les meilleures pratiques. Ce savoir est précieux pour l’interprétation, mais dangereux lorsqu’il est mélangé avec des chiffres concrets de l’entreprise.
L’art consiste à séparer proprement ces trois sources et à rendre transparent d’où provient chaque information.
L’approche : tout dans la fenêtre de contexte
Les LLMs modernes offrent des fenêtres de contexte de 100 000 tokens et plus. Cela ouvre une approche architecturale élégante : au lieu de laisser le modèle deviner quelles données pourraient être pertinentes, nous chargeons proactivement toutes les informations nécessaires dans le contexte.
Un système bien conçu fonctionne en plusieurs étapes : il analyse la question de l’utilisateur et identifie les sources de données pertinentes. Puis il exécute les requêtes SQL nécessaires. En parallèle, il parcourt la base documentaire via RAG. Et finalement, le LLM reçoit toutes ces informations regroupées – avec un étiquetage clair des sources.
Le modèle de langage devient ainsi un interprète et un communicateur, pas un générateur de faits. Il peut expliquer les chiffres, révéler les connexions, poser des questions de suivi, discuter des options d’action – mais il n’invente pas de données, car les vraies données sont déjà dans le contexte.
La transparence comme principe de conception
Un tel système doit intégrer la transparence dans son ADN. Chaque affirmation sur des chiffres concrets devrait citer sa source. L’utilisateur doit pouvoir retracer : cela vient-il de la base de données ? A-t-il été cité d’un document ? Ou est-ce une évaluation du modèle ?
Cette transparence n’est pas qu’une fonctionnalité technique – c’est la condition préalable à la confiance. Quiconque fonde des décisions commerciales sur des analyses assistées par IA doit savoir sur quoi il s’appuie.
La voie à suivre
La Business Intelligence avec l’IA n’est ni une utopie ni un effet de mode – c’est un défi d’architecture. La technologie est mûre, les modèles sont puissants, les interfaces existent. Ce qui manque à beaucoup d’entreprises, c’est une approche réfléchie qui exploite les forces des LLMs sans succomber à leurs faiblesses.
L’avenir appartient aux systèmes qui connectent intelligemment bases de données structurées, connaissances documentaires et modèles de langage – tout en rendant toujours transparent ce qui est fait et ce qui est interprétation. Les entreprises qui trouvent cet équilibre gagnent plus qu’un simple outil d’analyse supplémentaire. Elles gagnent un véritable sparring-partner pour de meilleures décisions en temps difficiles.
Et oui – c’est exactement ce sur quoi nous travaillons.