Alle reden gerade über KI in der Buchhaltung. Die Berater haben ihre Slides fertig. Die Softwareanbieter labeln ihre OCR-Tools um. LinkedIn ist voll mit Posts à la „So habe ich meine Finanzprozesse automatisiert – kommentiere FINANCE für meinen n8n-Workflow.“ Wrapper überall.
Ich bin mir ziemlich sicher: KI wird die Buchhaltung verändern. Aber nicht so, wie die meisten denken, und wahrscheinlich nicht so schnell, wie die Schlagzeilen suggerieren.
Das Begriffschaos

Fangen wir bei den Basics an, denn die Sprache drumherum ist ein Desaster. Wenn Leute „KI in der Buchhaltung“ sagen, können sie Folgendes meinen:
Regelbasierte Automatisierung: Wenn Rechnungsbetrag > 10.000, dann an CFO weiterleiten. Wenn „Innergemeinschaftliche Lieferung nach § 4 1b“, dann „USt_00″. Das ist keine KI. Das ist Code mit Marketingbudget.
Machine-Learning-Klassifikatoren: Trainierte Modelle, die Transaktionen anhand von Mustern kategorisieren. Die sind tatsächlich nützlich und gibt es seit Jahren. Aber sie generalisieren oft schlecht und sind schwer aktuell zu halten, weil sie meist eine Black Box sind.
OCR und Dokumentenextraktion: Rechnungen lesen und Lieferantennamen, Beträge, Daten extrahieren. Das ist inzwischen Standard. Und manchmal funktioniert es sogar.
Large Language Models: Unser liebstes neues Spielzeug. GPT, Claude, Gemini. Können Kontext verstehen, chaotische Inputs interpretieren, Sonderfälle behandeln. Aber auch: Zahlen mit absoluter Überzeugung halluzinieren.
Die meisten „KI-Buchhaltungs“-Produkte heute sind eigentlich ML-Klassifikatoren mit einem LLM-Chatbot obendrauf. Was okay ist, aber seien wir ehrlich, was wir da vor uns haben.
Wo KI heute schon funktioniert
Hinter dem ganzen Marketing-Gerede passieren echte Dinge:
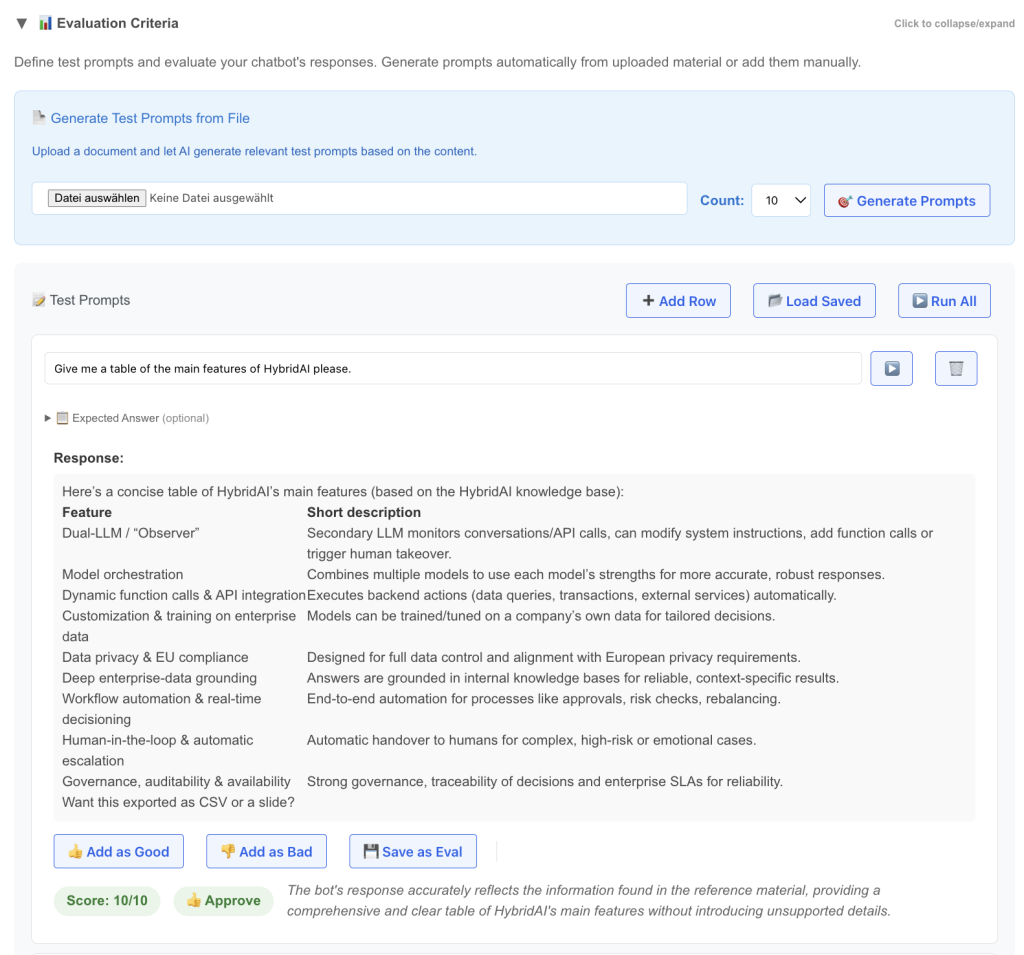
Belegerfassung und -extraktion. Moderne Systeme können Rechnungen in jedem Format lesen, jeder Sprache, jeder Scan-Qualität. Die Kombination aus Vision Models und LLMs hat dieses Problem im Prinzip gelöst. Für Sonderfälle braucht man noch Menschen, aber 80-90% Durchlaufquote ist machbar. Und wenn eine Rechnung in neuem Format kommt, funktioniert es trotzdem. Because AI.
Transaktionskategorisierung. Für Standardfälle sind ML-Modelle exzellent darin, euren Kontenrahmen zu lernen und konsistent anzuwenden. Sie werden freitagnachmittags nicht müde. Sie haben keine „kreativen“ Interpretationen von Kostenstellen. Übrigens: KI heißt nicht automatisch LLM. Es gibt eine tolle Familie von Encoder-Modellen unter 1 Milliarde Parameter, die bei Klassifikationsaufgaben hervorragend sind.
Anomalie-Erkennung. Doppelte Rechnungen finden, ungewöhnliche Beträge, Lieferanten, die plötzlich ihre Bankverbindung geändert haben. Mustererkennung im großen Stil ist genau das, was ML gut kann. Und schnell. Sehr nützlich für Betrugsprävention und Audit-Vorbereitung.
Natural Language Queries. „Zeig mir alle Marketing-Ausgaben über 50k vom letzten Quartal“ ohne SQL zu schreiben. Das funktioniert jetzt. Keine Magie, aber sieht aus wie Magie und spart echt Zeit. Warum nicht mal mit seinen Geschäftsdaten chatten? 😉
Der gemeinsame Nenner? Das sind alles Aufgaben, bei denen „meistens ungefähr richtig“ wertvoll ist und Menschen das Ergebnis leicht prüfen können.
Wo es interessant wird (und gefährlich)
Jetzt zum schwierigen Teil.
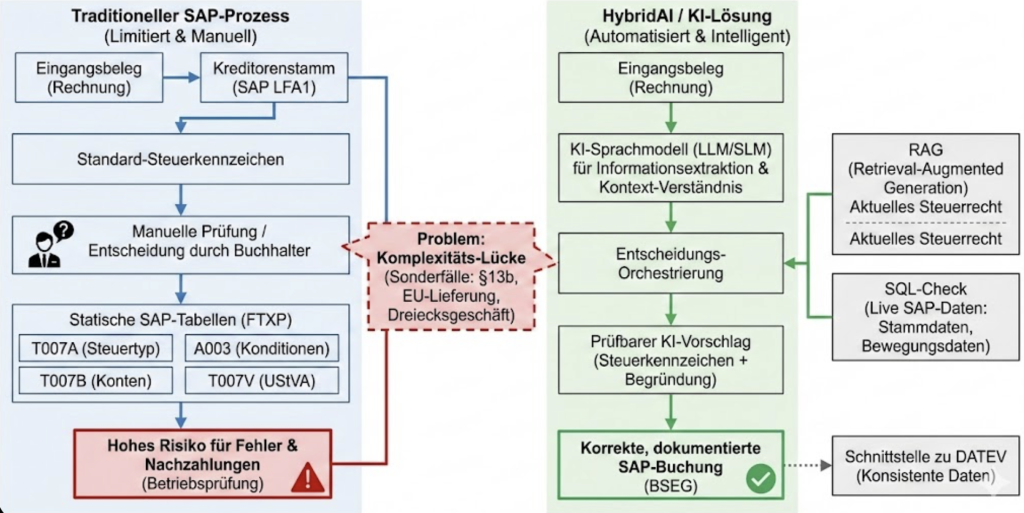
Sobald KI eine Entscheidung mit rechtlichen oder steuerlichen Konsequenzen treffen soll, ändert sich alles. Nehmen wir die Umsatzsteuer-Ermittlung bei einer Eingangsrechnung. Klingt einfach: 19%, oder?
Außer wenn nicht. Sitzt der Lieferant in einem anderen EU-Land? Ist das eine Dienstleistung oder eine Ware? Greift Reverse Charge? Ist es eine Bauleistung (§13b)? Ist der Lieferant überhaupt umsatzsteuerlich registriert? Dreiecksgeschäft? Gab es eine Pandemie mit Sondersteuersätzen?
Ich habe über dieses spezifische Problem mit Steuerkennzeichen in ERP-Systemen schon geschrieben. Kurzversion: Es gibt dutzende Sonderfälle, und Fehler bedeuten Prüfungsfeststellungen, Steuernachzahlungen und möglicherweise Betrugsvorwürfe.
Die unbequeme Wahrheit: LLMs sind sehr gut darin zu erklären, was Reverse Charge ist. Im akademischen Stil oder als Sonett. Aber sie sind gefährlich unzuverlässig darin zu bestimmen, ob eine konkrete Rechnung es anwenden sollte. Der Unterschied ist wichtig.
Das Halluzinationsproblem ist real. Ein LLM wird dir mit voller Überzeugung sagen, dass diese Rechnung eindeutig als innergemeinschaftliche Lieferung zu behandeln ist. Es zitiert vielleicht sogar die relevante EU-Richtlinie. Und liegt trotzdem komplett falsch, weil es nicht bemerkt hat, dass der Lieferant eine deutsche USt-ID hat, oder weil die Ware das Land nie verlassen hat. Ich habe ein paar Beispiele durch verschiedene LLMs gejagt – und sie hatten sehr starke Meinungen. Aber nicht unbedingt richtige. Deshalb bauen wir gerade eine VATBench, um das besser zu verstehen.
Wenn Claude oder GPT bei kreativem Schreiben einen Fehler macht, bekommt man einen seltsamen Satz. Wenn es bei der Steuerermittlung einen Fehler macht, bekommt man eine sechsstellige Nachzahlung bei der nächsten Prüfung.
Die hybride KI-Architektur, die wirklich funktioniert
Was heißt das also? Nicht „KI schlecht, Menschen gut.“ Die Antwort ist architektonisch. Ein Muster, das wirklich funktioniert, kombiniert drei Dinge:
LLMs für Interpretation. Lass das Sprachmodell die Rechnung lesen, relevante Fakten extrahieren, den Transaktionstyp klassifizieren, die Jurisdiktion des Lieferanten identifizieren. Das können sie gut – Informationsextraktion!
Strukturierte Regeln für Entscheidungen. Steuerrecht ist nicht kreativ. Es ist ein Entscheidungsbaum mit vielen Verzweigungen aber klarer Logik. Sobald man die Fakten hat, sollte die Regelanwendung deterministisch sein. Keine Kreativität nötig. Keine Halluzination möglich.
Transparente Audit Trails. Jede Entscheidung muss dokumentieren, warum sie getroffen wurde. Welche Rechnungsfelder extrahiert wurden. Wie der Lieferant klassifiziert wurde. Welche Regel das Steuerkennzeichen bestimmt hat. Wenn der Prüfer fragt, braucht man Antworten.

Die Kernerkenntnis: Frag das LLM nicht, welches Steuerkennzeichen es sein soll. Frag es, die Fakten zu extrahieren, dann wende deine Regeln an. Nicht halb so sexy wie „unsere KI macht alles automatisch.“ Aber es funktioniert.
Was das für CFO-Offices und Finanzteams bedeutet
Ein paar praktische Schlussfolgerungen:
Ihr werdet nicht ersetzt. Die „KI automatisiert Buchhaltung weg“-Takes werden meist von Leuten geschrieben, die noch nie einen Monatsabschluss gemacht haben.
Euer Job verändert sich. Weniger Dateneingabe, mehr Kontrolle. Weniger manuelles Matching, mehr Ausnahmebehandlung. Weniger Tippen, mehr Denken. Wenn ihr 60% eurer Zeit mit automatisierbaren Aufgaben verbringt, solltet ihr definitiv über KI reden.
Ihr müsst die Tools verstehen. Nicht wie man ein LLM von Grund auf baut (obwohl das echt Spaß macht). Aber wie sie funktionieren, wo sie scheitern, was sie können und was nicht. Die Finance-Leader, die erfolgreich sein werden, sind die, die KI-Anbieter mit echtem technischen Verständnis bewerten können.
Fangt mit eingegrenzten Problemen an. Versucht nicht, „die gesamte Finance-Funktion KI-fähig zu machen.“ Wählt einen schmerzhaften Prozess mit klaren Erfolgskriterien. Rechnungserfassung. Spesenkategorisierung. Intercompany-Abstimmung. Bringt das zum Laufen, lernt daraus, dann erweitert.
Fazit: KI in der Buchhaltung
KI in der Buchhaltung ist gleichzeitig real, nützlich und überhypt. Die Technologie funktioniert für Informationsextraktion, Mustererkennung und Natural-Language-Interfaces. Sie funktioniert nicht – nicht sicher – für unbeaufsichtigte Entscheidungen bei allem mit rechtlichen Konsequenzen.
Der Ansatz, der gewinnt, kombiniert die Interpretationsfähigkeit von LLMs mit der Präzision regelbasierter Systeme und der Aufsicht menschlicher Experten. Weniger aufregend als „vollautonome KI-Buchhaltung“, aber es ist das, was tatsächlich ausgeliefert wird, tatsächlich funktioniert und tatsächlich Prüfungen übersteht.