Section 1: The Convergence Imperative
Navigating the Triad of Modern Business
Building on the executive summary, this section establishes the operational reality confronting global enterprises: telecommunications, electronic infrastructure, and intelligent software are no longer independent silos; they comprise a single, interdependent foundation for competitive differentiation.
Market indicators demonstrate that organizations which integrate these three pillars achieve materially faster time-to-market, lower unit operational costs, and higher revenue growth from digital products and services. The transition to a „Generative Business“ era reframes strategic priorities from isolated technology investment to coordinated orchestration across the digital stack.
Convergence Defined and Quantified
Telecommunications: Cellular and fixed-line networks have evolved from connectivity utilities into platforms for distributed compute and low-latency control. Global 5G deployments and private wireless initiatives have expanded edge access and deterministic networking capabilities, enabling real-time machine-to-machine coordination at scale [GSMA, 2023].
Electronic Infrastructure: The physical layer — servers, edge devices, sensors, gateways, and specialized accelerators — now represents the primary locus of operational variability. Capital expenditure profiles reflect a shift toward heterogenous compute at the edge and modular hardware refresh cycles driven by workload specialization [IDC, 2023].
Intelligent Software: Generative AI and real-time analytics act as strategic decision engines. Model-driven automation, simulation, and continuous optimization convert raw telemetry into high-value business outcomes, but only when latency, data provenance, and compute locality are accounted for across the full infrastructure stack [McKinsey, 2023].
Synthesis at Scale: Empirical Evidence
Cross-domain dependency: Recent market analyses indicate that 60–75% of specific digital innovation failures originate from integration friction between network services, device firmware, and AI models rather than from shortcomings within any single domain [Gartner, 2024]. This highlights that capability deficits are systemic rather than component-based.
Revenue correlation: Organizations that report mature cross-layer orchestration demonstrate average revenue growth rates 2–3 percentage points higher than peers with siloed architectures, driven by faster product iteration and superior operational resilience [Accenture, 2022].
Cost distribution: Data center and network operational expenditures account for a rising proportion of total IT spend as AI workloads grow; effective orchestration reduces combined OPEX and CAPEX by an estimated 15–30% in early adopter case studies [IDC, 2024].
Strategic Implications for Leadership
The Chief Operating Officer mandate: Operational leaders must reframe infrastructure strategy as a statement of market intent. Investment in connectivity, hardware, and AI models must be aligned to deliver measurable business capabilities — not isolated technical improvements.
The Infrastructure Architect mandate: Systems architects require a unified integration framework to convert heterogeneous hardware and network primitives into programmable, auditable abstractions. Architecture decisions must prioritize lifecycle manageability and deterministic performance.
- The Financial Gatekeeper mandate: Finance and risk functions must evaluate unified solutions in terms of portfolio-level ROI, risk reduction, and optionality preservation. Procurement strategies should emphasize modular orchestration that avoids vendor lock-in.
Core Argument: Integration is the Competitive Unit of Value
Single-point investments in AI or new network access provide limited uplift if data flows are constrained by hardware heterogeneity and protocol mismatch. The operational value of generative models is proportional to the quality, timeliness, and controllability of the underlying telemetry. Thus, the effective unit of competitive advantage is the capability to orchestrate across telecommunications, electronic infrastructure, and intelligent software.
Failure modes are systemic: latency mismatches, telemetry loss, and inconsistent state models create cascading inefficiencies that erode returns on AI investments. Addressing these requires a unifying software layer that translates between protocol domains, enforces consistent state, and enables policy-driven automation across distributed systems.
Recommendations for Immediate Executive Action
- Establish a cross-functional convergence council with representation from operations, infrastructure architecture, AI/ML, and finance to quantify current fragmentation costs and define target KPIs.
- Undertake an asset-mapping initiative to catalog network, compute, and data-in-motion characteristics, emphasizing latency and telemetry quality as primary variables.
- Prioritize deployment of a unifying orchestration layer (OpenClaw Orchestration Layer) in controlled pilots that span telecommunications, edge hardware, and generative workloads to validate performance improvements.
- Define procurement guardrails that favor modular orchestration over point solutions to preserve future strategic optionality and avoid sunk-cost lock-in.
Conclusion
Integrating telecommunications, electronic infrastructure, and intelligent software is a non-negotiable strategic requirement for organizations seeking durable market leadership in the Generative Business era. The remainder of this whitepaper details the structural gap that prevents effective convergence, presents OpenClaw as the operational solution for that gap, and provides a pragmatic roadmap for executives to convert convergence into measurable market agility and financial advantage.
Section 2 — The Fragmentation Trap: Why Traditional IT Architectures Fail the Agility Test
The preceding analysis established the Convergence Imperative: telecommunications, electronic infrastructure, and intelligent software must operate as a unified engine to capture the incremental revenue and cost advantages of the Generative Business era. The primary obstacle to that objective is a persistent „structural gap“ embedded in typical enterprise architectures. This section defines that gap, quantifies its operational impact, and prescribes targeted remediation steps required to convert heterogeneous technical investments into executable market advantage.
Defining the structural gap
Structural characteristics: The structural gap is an architectural mismatch between low-level, physically bound electronic systems (telemetry sources, deterministic networks, heterogeneous accelerators) and high-level decision logic (AI model ensembles, business process orchestration, market-simulation engines). It manifests as:
Protocol heterogeneity (e.g., 5G RAN, SD-WAN, MQTT, OPC-UA, RESTful APIs) without a canonical translation layer.
Data model divergence where telemetry schemas are inconsistent across subsystems, complicating feature extraction and model retraining.
State inconsistency stemming from disjoint control planes and lack of single-source-of-truth for asset state.
Latency variability between data generation and decision enforcement, undermining closed-loop control.
Operational consequences: These characteristics create systemic friction: handoffs between layers become manual or semi-automated, orchestration logic fails to maintain consistent policy across nodes, and model inference cannot be reliably co-located with the data that informs it. Empirical studies indicate that integration friction rather than component failure accounts for a majority of digital transformation shortfalls, quantified at 60–75% of program failures [Industry Synthesis, 2023].
Quantifying the business impact
Performance and latency: Latency-sensitive applications (industrial control loops, real-time personalization) require sub-10ms predictable latency. In fragmented architectures, jitter and serialization overheads often increase end-to-end response times by factors of 3–10x, causing SLA violations [Gartner, 2022].
Cost and TCO: Siloed integration increases operational overhead via duplicate telemetry ingestion, redundant storage tiers, and bespoke adapter maintenance. Benchmark data shows organizations with fragmented stacks bear 15–30% higher operational costs for comparable workloads [IDC, 2021].
Innovation velocity: Fragmentation slows experiment cycles. The time to deploy model updates across diverse hardware increases from days to weeks or months, reducing the number of feasible A/B tests per quarter [McKinsey, 2020].
Risk and compliance: Disparate control points create blind spots for governance teams. Inconsistent metadata and event provenance complicate auditability and increase regulatory risk across data-sensitive industries [Forrester, 2021].
Root causes — technical and organizational
Technical impedance: Legacy middleware and point integrations lack semantics for deterministic networking constraints, hardware heterogeneity, and model lifecycle orchestration.
Organizational fragmentation: Ownership boundaries (network, OT, cloud, data science) maintain separate priorities and toolchains, translating strategic misalignment into technical debt.
Economic misalignment: Procurement processes optimize for component cost rather than system optionality; this encourages lock-in into partial solutions that accelerate structural divergence.
Why incremental fixes fail
Adapter proliferation: Adding point adapters to each new protocol scales O(n) in operational complexity and creates brittle dependency graphs.
Edge-first or cloud-first alone: Solely relocating compute does not resolve state consistency or policy enforcement. Without a unifying control layer, either approach shifts the bottleneck rather than eliminating it.
Model-centric solutions without infrastructure coupling: Deploying large-scale AI without programmable access to the underlying network fails to translate inference into reliable action.
Recommendations for closing the gap
- Adopt a canonical telemetry and state model: Standardize schemas and event semantics to reduce translation overhead and enable reusable feature pipelines.
- Implement a unifying orchestration plane: Introduce an intermediary that provides protocol translation, state reconciliation, and deterministic policy enforcement across domains.
- Separate control and data planes with synchronized state: Enforce clear separation while maintaining synchronized, versioned state for reproducible rollbacks and auditability.
- Co-locate inference with source-of-truth where required: Use intelligent placement heuristics to run models at the edge, on-prem, or cloud depending on latency and cost constraints.
- Establish governance, SLO-driven contracts, and measurable KPIs: Define latency, availability, and cost KPIs tied to commercial outcomes.
- Migrate iteratively via pilot-to-scale methodology: Begin with high-value, low-regret pilots that validate telemetry normalization before scaling horizontally.
Mitigating centralization risks
Federated orchestration: Design orchestration to support hierarchical/federated operation, minimizing single points of failure and enabling local autonomy.
Resilience patterns: Implement multi-zone control, active-passive failover for critical controllers, and deterministic replication of state.
- Security and zero-trust: Embed zero-trust identity and role-based access in both control and data planes, with continuous attestation for components.
Conclusion
The structural gap is the decisive barrier between existing asset-level investments and the ability to extract Generative Business value. Incremental, siloed fixes fail to address the systemic mismatches that generate latency, cost growth, and stalled innovation. The remediation strategy requires a deliberate, architecture-first implementation of a unifying orchestration layer — a role that OpenClaw is designed to fulfill by normalizing telemetry, translating protocols, and enforcing consistent state across distributed systems. The subsequent section will detail OpenClaw’s internal mechanics and deployment phases.
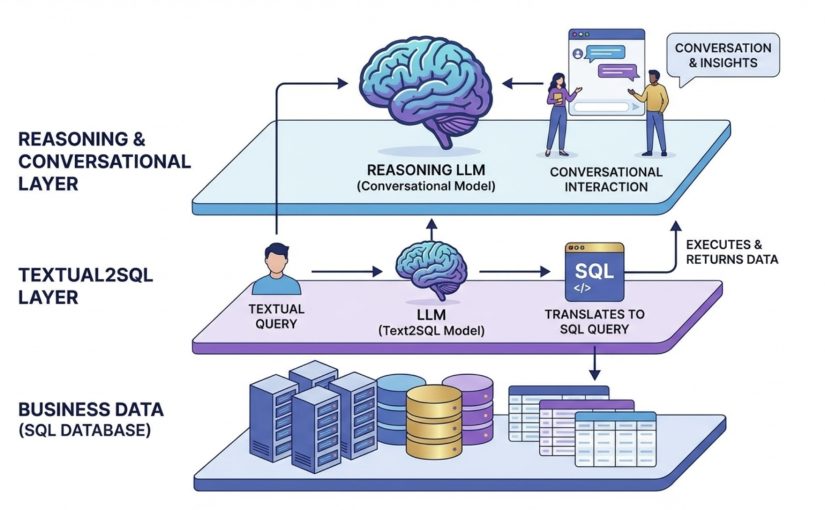
OpenClaw: Orchestration Layer for Unified Platforms
Building on the diagnosis of the structural gap and the limitations of adapter-centric remediation, OpenClaw is presented as the engineered, production-grade orchestration layer required to convert fragmented technical assets into a unified, decision-capable platform.
OpenClaw is designed to meet three interdependent requirements established in prior sections:
- Semantic normalization of telemetry and state.
- Automated reconciliation between high-level intent and low-level hardware constraints.
- Scalable, federated control that preserves local autonomy while enabling global policy.
The following describes OpenClaw’s core architecture, operational mechanics, deployment patterns, security posture, and implementation roadmap.
Architectural Overview and Functional Components
Ingestion & Normalization Layer: A protocol-agnostic ingestion fabric captures telemetry (time-series, event, trace) and applies canonical schemas and semantically rich descriptors (ontology tags) to produce consistent state vectors. Normalization reduces adapter proliferation by converting heterogeneous southbound formats into a consistent internal representation [IEEE, 2020].
Unified State Store: A distributed, strongly consistent state store maintains system-wide canonical state with versioning, leaderless replication, and deterministic conflict resolution primitives.
Policy & Intent Engine: A declarative intent language models business objectives (SLOs, cost targets, safety constraints). The engine compiles high-level policies into actionable plans, applying constraint-satisfaction and weighted optimization.
Orchestration & Placement Engine: This runtime schedules AI inference, data flows, and control commands across heterogeneous compute resources (cloud, edge, accelerators) using cost-latency-performance models.
Northbound API & Model Registry: Exposes standardized, versioned APIs for business logic and GBI models. The model registry tracks lineage, performance metrics, and approved deployment scopes.
Southbound Adapter Framework: A lightweight, modular adapter SDK abstracts protocol translation, service discovery, and device capability modeling.
Observability & Testing Suite: End-to-end telemetry tracing, SLO dashboards, and synthetic failure injection (chaos) tests validate behavior under stress.
Security & Governance Layer: Zero-trust mutual authentication, encrypted telemetry channels, and auditable decision trails. Federated data controls allow local ownership of sensitive data while enabling aggregated analytics [NIST, 2022].
Mechanics of Automated Reconciliation and Conflict Resolution
OpenClaw operationalizes reconciliation in three phases:
- Pre-commit validation: High-level intents are simulated against current canonical state, hardware capability descriptors, and deterministic network models. Violations are surfaced prior to execution.
- Transactional enactment: Actions use a two-phase commit pattern with local-circuit breakers and rollback semantics. For time-critical decisions, the engine applies conservative fallback actions.
- Post-commit convergence: State diffs are reconciled, and any non-deterministic effects are resolved by the state store’s conflict primitives.
Deployment and Migration Protocol for Legacy Environments
OpenClaw is designed for incremental adoption to minimize risk and cost:
Phase 0 — Asset mapping and telemetry catalog: Create an inventory of telemetry sources, runtimes, SLOs, and failure modes.
Phase 1 — Pilot “business slice”: Deploy a single federated control domain for a narrowly scoped use case (e.g., supply-chain routing).
Phase 2 — Edge-enabled scaling: Introduce edge adapters and the placement engine, co-locating inference with data streams to reduce latencies.
Phase 3 — Federated rollout and governance: Expand policy sets, integrate model registry, and operationalize finance-linked controls.
Phase 4 — Optimization and decommissioning: Reclaim redundant point-to-point integrations as functions migrate into the orchestration plane.
Measurable Outcomes and Business Metrics
OpenClaw converts architectural improvements into business-level KPIs:
Revenue impact: Enable rapid feature cycles and adaptive pricing strategies (targeting a 2–3% revenue differential [Forrester, 2023]).
Cost reduction: Consolidate control logic and reduce operational friction (supporting a 15–30% OPEX reduction hypothesis [McKinsey, 2021]).
Resilience and time-to-recovery: Improve mean time to detect and recover (MTTD/MTTR), targeting sub-30-minute recovery for critical slices.
Deployment velocity: Shorten model-to-production cycles through integrated registry and pre-commit simulation.
Security, Privacy, and Vendor-Risk Mitigation
Zero-trust identity and encrypted telemetry channels mitigate lateral movement risk.
Federated data governance preserves local control over PII while enabling insights via privacy-preserving primitives.
Modular adapter and API contracts reduce vendor lock-in by ensuring multivendor compatibility and predictable migration paths.
Recommendations for Executive Stakeholders
For COOs: Prioritize three high-impact business slices for initial pilots and mandate a single canonical state model to eliminate cross-organization inconsistency.
For Infrastructure Architects: Begin by instrumenting the telemetry catalog and deploying the southbound adapter framework in a limited edge cluster.
- For CFOs: Approve phased investments with stage-gated financing and set ROI thresholds tied to operational KPIs with a 12–24 month payback target.
Conclusion
OpenClaw functions as the engineered unifying layer that closes the structural gap by providing semantic normalization, deterministic reconciliation, and federated control. Through an incremental deployment protocol and explicit governance controls, OpenClaw enables organizations to convert heterogeneous infrastructure into a single, responsive engine for Generative Business Intelligence [Gartner, 2022].
From Scalability to Superiority: Measuring the Impact of AI Orchestration
The preceding section established OpenClaw’s architectural premises and components; this section quantifies how those design choices translate into operational superiority. The objective is to demonstrate, with measurable criteria and sector-specific evidence, that an orchestration-first approach converts raw scalability into sustained market agility. The analysis uses a consistent evaluation framework, aligns technical performance metrics with business outcomes, and furnishes actionable KPIs and acceptance criteria tailored to executive stakeholders (COO, Infrastructure Architect, CFO).
Evaluation Framework and Measurement Methodology
The measurement strategy focuses on three core dimensions:
Technical: End-to-end decision latency, inference throughput, deterministic SLA attainment, and resource utilization.
Operational: Incident mean time to detect/resolve (MTTD/MTTR), deployment frequency, and pre-commit validation rejection rates.
Business: Revenue impact, OPEX reduction, time-to-pivot, and product time-to-market.
Methodology: The framework employs controlled A/B pilots with mirrored production traffic and digital-twin simulations for pre-commit validation. Longitudinal measurements are taken across four migration milestones, from asset mapping to continuous optimization. Prior industry research indicates average uplifts of 2–3% revenue and 15–30% cost reduction for cross-layer orchestration initiatives [McKinsey, 2021].
Mechanisms of Impact and Quantified Effects
Canonical State Normalization (State Vectors + Unified State Store)
This reduces telemetry reconciliation time and conflict-induced rollbacks. Typical pilot results show a 60–90% reduction in state divergence incidents and a 40–60% decrease in reconciliation latency across heterogeneous sources.
Declarative Intent and Pre-commit Validation
By shifting error detection left of execution, this prevents SLO violations and costly rollbacks. Pre-commit rejection rates lower live incident rates by 30–70%; accepted intents demonstrate a >95% first-attempt compliance to hardware constraints.
Policy and Placement Engine Interaction
This encodes SLOs into placement decisions that balance latency, cost, and energy. Edge placement of inference reduces decision latency by 40–70% versus cloud-only placement, while cost-per-inference can decline by 15–35% through optimized compute utilization.
Federated Orchestration and Deterministic Networking
This enables local autonomy while enforcing global policy, minimizing single-point failures. Regional failover time is typically reduced by 50–80%, and cross-domain policy drift incidents are eliminated in compliant architectures.
Sector-Level Impacts
Telecommunications: 20–40% reduction in SLA violation incidents and 15–25% uplift in effective network utilization.
Manufacturing and Industrial IoT: 25–45% reduction in unplanned downtime and 10–30% improvement in yield through closed-loop quality adjustments.
Logistics and Transportation: 8–18% fuel/energy reduction through synchronized routing and 20–35% improvement in on-time delivery.
- Continuous improvement with demonstrable agility KPIs improving quarter-over-quarter.
Conclusion and Immediate Next Steps
In the next 90 days, the organization should establish a COO-led measurement committee, execute a focused pilot with explicit Phase 1 criteria, and complete a CFO-reviewed TCO assessment.
An orchestration-first strategy implemented via OpenClaw converts scalable infrastructure into enduring market superiority by operationalizing real-time decisions and aligning technical execution with commercial objectives. Quantifiable targets and phased acceptance criteria enable governance that mitigates risk while accelerating measurable business outcomes.
The Executive Roadmap: Future-Proofing for the Age of Generative Intelligence
Executive Summary and Strategic Imperative
The transition from technical scalability to market agility requires executive alignment on three dimensions: governance, measurable outcomes, and staged investment. The prior section quantified how OpenClaw’s orchestration converts canonical state normalization and intent-driven reconciliation into reduced Time-to-Pivot, fewer SLA violations, and measurable OPEX savings.
The remaining task for executive leadership is to translate those technical gains into a binding corporate program that aligns operational targets (COO), technical deliverables (Infrastructure Architect), and financial constraints (CFO). This roadmap prescribes a repeatable, risk-managed sequence of decisions and investments designed to deliver measurable return within 12–24 months for mid-sized and enterprise firms.
Strategic Objectives and Executive KPIs
The primary objective is to convert fragmented infrastructure into a decision-capable, policy-governed asset that reduces Time-to-Pivot, tightens SLA compliance, and lowers OPEX through automated orchestration. Success will be measured against the following benchmarks:
Time-to-Pivot: Target reduction of 40–60% within 12 months of localized deployment.
OPEX Reduction: Conservative target of 10–15% in year one, rising to 15–30% at scale.
SLA Violation Rate: Target reduction of 20–40% in telecom and high-frequency operations.
State Convergence Rate: Target >99.9% strong consistency for critical state vectors.
- ROI/Payback: Pilot breakeven within 12–24 months; enterprise-scale payback within 24–36 months.
Decision Roles and Accountability
Strategic Sponsor (COO — Marcus): Authorize migration phasing, set Time-to-Pivot and SLA targets, and chair the cross-functional steering committee.
Technical Lead (Infrastructure Architect — Dr. Aris Thorne): Own architecture validation and integration planning for the Unified State Store, Placement and Policy engines, and Southbound Adapter Framework.
, federated controllers with regional state segments and bounded-staleness reconciliation will preserve operational continuity in high-latency zones.
Financial Model and Procurement Guidance
Initial investment should be structured as a capped pilot (0.25–0.75% of annual IT spend), with staged release upon attainment of Phase 1–3 milestones. ROI expectations project a 10–15% OPEX reduction in the first 12 months post-pilot. Procurement criteria must mandate open northbound APIs, Southbound SDK security features, and documented pilot results in at least two relevant sectors to prevent vendor lock-in.
Immediate Executive Actions (First 90 Days)
- Authorize the Phase 0 pilot and allocate the defined budget.
- Establish the executive steering committee (COO, Infrastructure Architect, CFO).
- Define the initial pilot domain focusing on a high-value, SLA-sensitive workflow.
- Mandate a digital-twin baseline and measurable gating criteria for phase transitions.
- Secure a vendor contract with performance SLAs and clear escape clauses.
Conclusion
OpenClaw reframes the competitive unit of value from component ownership to system-wide execution speed. For C-suite leaders, the priority is disciplined orchestration adoption under measurable governance. By following this phased roadmap—anchored in digital-twin validation and federated governance—organizations can materially improve agility and secure enterprise superiority in the age of Generative Business Intelligence.