Design principles, performance, security, scaling and resilience — and why most agent platforms quietly fall apart on exactly those dimensions.
There’s a new family of AI agent runtimes that has emerged over the last few months, often grouped colloquially as “Claws” or sometimes “Clawz”: OpenClaw (formerly MoltBot, the personal experimentation framework), PaperClip (the agentic framework from Sebastian Küpers and the Serviceplan Group), Hermes-Agent, and our own HybridClaw. What connects them is an architectural break with the first wave of agent platforms: away from monolithic cluster setups, toward lean, locally executable runtimes that boot in seconds and can still be operated in production.
This article is about the architecture and design principles that make HybridClaw a lightweight runtime by deliberate choice — and why exactly that choice is what allows performance, security, scaling and resilience to be addressed cleanly in the first place.
Why “Lightweight” is the Right Model for Agents
The first generation of agent platforms borrowed its blueprint from classical microservice stacks: Kubernetes, service mesh, a dedicated cluster for the vector DB, another for the queue, a third for observability. That blueprint works well for hyperscalers and high-traffic consumer APIs. For agents, it’s the wrong model.
An agent is not a stateless request handler. An agent is closer to a long-running process that composes skills, invokes tools, queries models, drives browsers, and builds up a trajectory along the way — a trajectory that will later be needed for evals, replay and audit. If you press this kind of object into a classical microservice stack, you optimise the wrong axis: you get high availability for components that rarely fail, and at the same time no good answers to the questions that actually hurt in agent operations — “Which skill update broke performance last week?”, “Which tool call set the wrong VAT code?”, “Can we reproduce the run from Tuesday at 11:43?”
HybridClaw takes the opposite path. The runtime is a single Go-style binary that boots on a laptop in under a second. No cluster, no Kubernetes, no Helm chart as a prerequisite. Production deployments scale out to multiple worker processes, but that’s an option, not an entry fee. People who want to start with agents don’t need a DevOps team. People who want to run them in production have the same code path — just with more workers and a control plane on top.
This architectural decision isn’t an aesthetic. It’s the foundation for six concrete design principles that shape every other property of the runtime.
The Six Design Principles in Detail
1. Lightweight by Default
Single binary, no cluster, no mandatory state store. The runtime itself holds no shared mutable state — coordination happens through the HybridAI control plane (queue + leader election) when a multi-node setup is run. Until then, SQLite or the local filesystem is enough.
2. Local-First Execution
Agents run where the data lives. Skills, tool calls and browser automation execute in the user’s environment by default. No cleartext data leaves the perimeter without explicit routing through the control plane. This isn’t only a GDPR feature — it’s also a latency argument. Anyone trying to route browser automation from a corporate data centre, through public cloud, onto a local ERP login screen has already lost.
3. Deterministic Skills
Skills are versioned, content-addressed manifests. Same input + same skill version = same trajectory. This is the point where many agent frameworks quietly cheat: they stitch together the system prompt at runtime from three templates, pull values out of environment variables, and hope it stays reproducible. It doesn’t. If skills aren’t deterministically addressable, evals are not meaningful and rollbacks are not safe. HybridClaw treats skills like code artefacts: signed, versioned, hash-identifiable.
4. Sandboxed Tool Use
Every tool runs in an isolated execution context with explicit capability grants. Browser automation, file access, shell commands — all gated by signed manifests and runtime policy. Default-deny. A skill that needs to send email doesn’t get shell access. A skill that analyses logs doesn’t reach the mail API. This sounds obvious, but in practice it’s the point where most agent demos fall apart in a real compliance review.
5. Content-Addressed Artifacts
Trajectories, skill outputs and audit records are content-addressed. Every entry gets a hash that uniquely identifies its content. Entries are chained — tampering is detectable. This makes traces reproducible, replayable, and forensically defensible. It’s the prerequisite for being able to prove to an auditor seven years from now what an agent did and when. Without this property, audit logs are just pretty tables with no legal weight.
6. Observable Everything
Every span, every tool call, every model invocation emits structured telemetry by default. Not as a plugin, not as an optional extension, not as “we’ll add it later”. Operators get dashboards for latency, cost-per-task, eval scores and safety incidents out of the box. Running an agent system without this telemetry is running on blind trust — and blind trust is not a strategy in an enterprise context.
Performance & Scaling: From the Laptop to the Worker Fleet
Scalability in agent runtimes is rarely a problem of raw request rate. An agent fleet with fifty agents running in parallel is not what makes classical web backends sweat. What makes it hard is that agents run long, make an unpredictable number of tool calls, and stream model responses rather than waiting for them. HybridClaw addresses this on five levels.
Agent-level concurrency. Every agent has its own task queue. A long-running tool call — say, a browser session waiting 90 seconds for a confirmation page — doesn’t block sibling agents. This is not a trivial pattern; many early agent frameworks had a global queue here and broke on exactly that.
Batched LLM calls. When several agents query the same model at the same time, in-flight prompts are batched where the provider allows it. This noticeably reduces cost and latency for high-volume workloads. With 100+ requests per minute to the same model, it’s not “nice to have” — it determines the token bill at the end of the month.
Multi-layer cache. Skill outputs, retrieval results and tool responses are cached at three levels: in-memory for the active task, on-disk for the agent process, and cross-worker on explicit opt-in. The last one is deliberately not the default — cache coherence between workers is one of the most common sources of bugs in distributed agent systems.
Worker scaling. Horizontal scaling happens through additional worker processes. Coordination runs through the HybridAI control plane (queue + leader election), not inside the runtime itself. This is the architectural decision that keeps the single-binary promise alive: the runtime knows nothing about other workers. It just does its job. The cluster concern lives one layer up, on purpose.
Streaming everywhere. Model outputs, tool results and channel responses stream end-to-end. There’s no waiting for a complete model completion before the next step starts. That doesn’t only reduce perceived latency in chat interfaces — it also lets downstream tools start working while the main model is still thinking.
Security: Assume Hostile Inputs
Agent platforms multiply the blast radius of every security flaw. A classical chatbot that gets jailbroken produces, at worst, embarrassing text. An agent that gets jailbroken can send emails, pay invoices, file tickets, write to databases. Anyone running agents seriously has to assume hostile inputs — both from outside (prompt injection in an incoming email) and from inside (a model that hallucinates and believes itself to be authorised).
HybridClaw stacks six security layers, all of them default-on:
Secrets vault. Tools never see raw credentials. Passwords, API keys and OAuth tokens are referenced by ID and resolved at runtime through the control plane. Audit logs and trajectories only ever contain the IDs, never the cleartext. Grepping the logs won’t yield secrets.
RBAC & capability grants. Permissions are granted per agent, per skill, per tool. Default-deny: whatever isn’t explicitly allowed is forbidden. That includes seemingly innocuous things like network access.
Sandboxed execution. File access, shell commands and browser automation run in isolated contexts with no host network access by default. A skill that parses PDFs doesn’t reach the internet — unless that specific capability is explicitly granted.
Signed skill manifests. Skills are verified against signed manifests before they run. No unsigned code paths in production. This blocks supply-chain attacks via tampered skill updates — a risk that is systematically underestimated in this space.
Human-in-the-loop gates. High-impact actions — money transfers, bulk deletes, outbound mail to customers — can require human approval. Configurable per skill, audit-logged. If you want an agent to wire ten thousand euros, that should require a second click.
Tamper-evident audit log. Every action is content-addressed and chained. Operators can prove what an agent did, when, under whose authority, with which skill version, against which input, producing which output, at what latency, at what cost. In the managed cloud, the log is additionally mirrored to an external append-only store and retained for seven years in an audit-grade format.
Resilience: Failure as the Default Case
This is one of the most important differences between demo agents and production agents: production agents fail. Models time out, tools return unexpected errors, networks partition, a vendor changes its API without notice. Anyone building agents only for the happy path is building toys.
HybridClaw treats failure as the default case, not an edge case. Concretely:
| Failure Mode | Runtime Behaviour |
|---|---|
| Transient model error | Exponential backoff; on repeated failures, fall back to a configured alternative model. |
| Tool exception | Error is captured in the trajectory; agent can retry, choose a different tool, or escalate. |
| Worker crash | Task is requeued; idempotent skills resume from the last checkpoint. Non-idempotent skills surface a manual replay decision. |
| Bad skill version | Eval gate blocks deploy if regression score crosses a threshold. If it slips through anyway: rollback is a single command and content-addressed. |
| Dead-letter queue | Tasks that exceed the retry budget land in a DLQ for human inspection — never silently dropped. |
| Cost runaway | Per-agent budgets cap spend. Soft limits warn; hard limits stop new tasks until lifted manually. |
The last entry is the one that tends to be missing from competing platforms — and the one that causes the most expensive damage. An agent stuck in a loop, racking up eight thousand euros in token costs over four hours, is not a theoretical scenario. We’ve seen it in real setups. Cost-runaway protection belongs on the same tier as security and audit, not in some “premium” plan.
Self-Hosted Runtime, Managed Control Plane — or Both
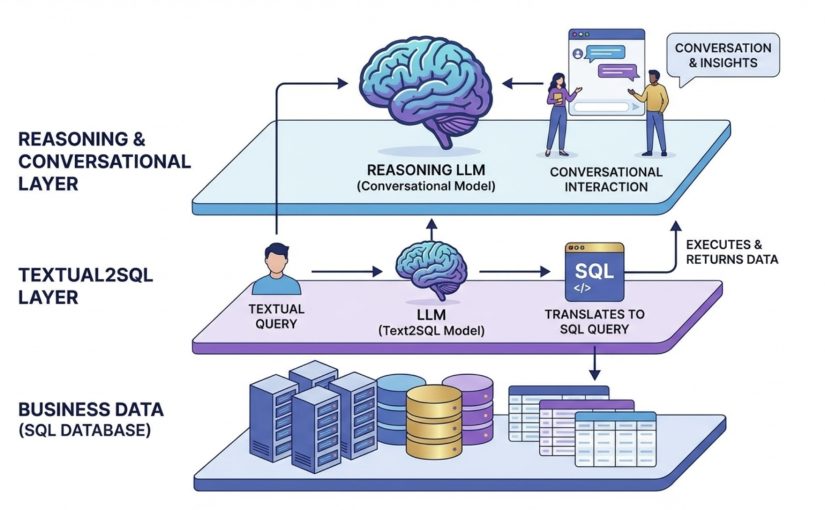
Architecturally, HybridClaw separates two layers cleanly: the runtime (open source, lightweight, self-hostable) and the control plane (managed, EU-hosted, with compliance features built in).
The runtime handles agent execution, skill manifests, tool sandboxing, browser automation, local trajectory capture, and the multi-channel adapters (Discord, Teams, WhatsApp, email, web, terminal). It’s openly available on GitHub, runs locally, and can be operated on your own infrastructure.
The control plane handles RAG and memory, the company brain, RBAC, the secrets vault, the audit log, observability dashboards, skill evals and deploy gates, budget controls, EU hosting, and GDPR/AI Act compliance. It lives on hybridai.one and is operated by us.
Both layers are independently deployable. The most common configurations we see with customers:
- Fully managed cloud. Fastest path to production, operations handled by us, EU hosting on Hetzner.
- Self-hosted runtime + managed control plane. Data control at the customer perimeter, but no need to build your own audit storage or eval setup.
- Fully self-hosted. Maximum control, everything on your own infrastructure, local models via Ollama or vLLM, up to 80% token savings compared to cloud LLMs.
- Hybrid deployment. Managed-cloud agents delegate sensitive tasks to self-hosted agents. Works over agent-to-agent messaging.
Important: skills and memory are portable between deployments. Starting in the managed cloud and migrating later doesn’t mean rebuilding from scratch.
Conclusion: Lightweight Is a Choice, Not a Shortcoming
When people hear “lightweight runtime”, they sometimes hear “toy” or “not enterprise-grade”. That would be a misreading. Lightweight here means: no complexity that isn’t justified by the use case. An agent doesn’t need a Kubernetes cluster to classify invoices. An agent doesn’t need twelve microservices to prepare an SAP posting. What it needs is a clean skill model, signed manifests, isolated tools, a tamper-evident audit log, and telemetry that shows whether it’s doing its job.
That is exactly what HybridClaw is. An open-source runtime that boots in under a second, ships as a single binary, and still brings every property you need to run in regulated, production-grade environments. The control plane on top is optional — but for anyone who doesn’t want to build GDPR compliance, seven-year audit retention and EU hosting themselves, it’s the substantially calmer route.
For the architecture in detail: hybridclaw.io/architecture. To get hands-on: GitHub for self-hosted, hybridai.one for the managed cloud. There’s a live demo at re:publica 26 in Berlin, where we’ll have a HybridClaw agent write a book on stage. Let’s see how far it gets.
Related reading: