Wenn heute von Fortschritten bei generativer KI die Rede ist, heißt es schnell: „Das neue Modell ist besser.“ Gemeint ist dann je nachdem: mehr Wissen, bessere Antworten, stabileres Verhalten, bessere Benchmarks oder ein angenehmerer Stil. Technisch sauber ist diese Aussage aber selten, denn in der Praxis entstehen Verbesserungen auf mehreren Ebenen, die man auseinanderhalten sollte. Sonst redet man aneinander vorbei.
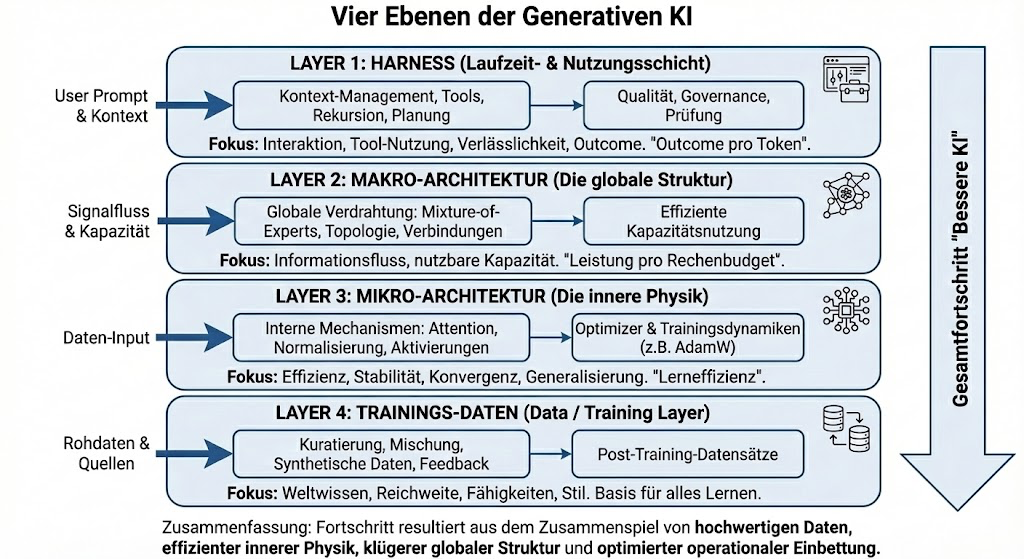
Ganz am Anfang stehen die Trainingsdaten. Sie legen fest, was ein Modell überhaupt lernen kann. Welche Welt es sieht, welche Themen es kennt, welche Sprachen es versteht. In den letzten Jahren kamen viele Sprünge nicht nur daher, dass Modelle größer wurden, sondern weil Daten besser kuratiert, gemischt oder gezielt synthetisch ergänzt wurden („Synthetic Data Revolution“). Zwei Modelle mit identischer Architektur können sich massiv unterscheiden, wenn die Datenbasis eine andere ist. Das wird oft unterschätzt, weil Daten selten öffentlich sind – ihr Effekt ist aber enorm. Und im Finetuning kann man Modelle gezielt neuen Spezialthemen aussetzen, um ihre Kenntnisse zu vertiefen.
Darauf baut dann die Mikro-Architektur auf. Hier geht es um das Innenleben des Modells: Attention, Normalisierung, Optimizer, Trainingsstabilität, Post-Training etc. Viel Fortschritt entsteht hier leise und vergleichsweise unspektakulär (jedenfalls außerhalb der Hardcore AI-Bubble). Modelle gleicher Größe sind heute schlicht besser trainiert als noch vor ein oder zwei Jahren und erzielen bessere Werte in den Benchmarks.
Die Makro-Architektur beschreibt dann die globale Struktur des Modells. Wie Information durch die Layer fließt, welche Teile wann aktiv sind und wie Kapazität genutzt wird. Konzepte wie Mixture-of-Experts oder lernbare Hyper-Connections zwischen Layern verändern nicht einzelne Bausteine, sondern die Gesamtorganisation. Gerade bei Small Language Models ist das ein wichtiger Hebel, weil man mehr Leistung herausholen kann, ohne proportional mehr Rechenbudget zu brauchen.
Am meisten unterschätzt wird jedoch der Harness. Er entscheidet, wie ein Modell tatsächlich eingesetzt wird. Welche Informationen in den Kontext gelangen, wie mit langen Kontexten umgegangen wird, ob Tools genutzt werden dürfen, ob geplant, geprüft oder rekursiv nachgebessert wird. Spätestens hier zeigt sich: Kontext ist keine kostenlose Ressource. Wer alles in den Prompt kippt, bekommt selten bessere Antworten, sondern oft instabiles Verhalten (Stichwort: „Context Rot“).
Ansätze wie Recursive Language Models zeigen sehr schön, wie groß der Effekt reiner Harness-Innovationen sein kann. Das Modell bleibt gleich, aber der Kontext wird nicht mehr blind gefüttert, sondern aktiv durchsucht und strukturiert. Plötzlich werden Aufgaben lösbar, die vorher außerhalb der Reichweite lagen. Nicht, weil das Modell schlauer ist, sondern weil es besser genutzt wird.
Im Unternehmens-Umfeld ist das nichts Neues. Der Unterschied zwischen einem Demo-Chatbot und einem produktiven System liegt fast nie im Modell. Er liegt in Tests, Staging, Zugriffskontrollen, Auditierbarkeit, deterministischer Tool-Nutzung und sauberer Evaluation. Kurz gesagt: im Harness.
Diese Vier-Layer-Sicht hilft, Fortschritt realistischer einzuordnen. Daten bestimmen, was gelernt werden kann. Mikro-Architektur bestimmt, wie gut gelernt wird. Makro-Architektur bestimmt, wie viel davon nutzbar ist. Und der Harness entscheidet, wie viel davon am Ende wirklich ankommt. Wer nur auf „das Modell“ schaut, verpasst oft genau die spannendsten Entwicklungen.