In den letzten Monaten erleben wir einen regelrechten Boom bei KI-Anwendungen – von ChatGPT über Copilot bis zu spezialisierten Enterprise-Lösungen. Eine Frage, die dabei immer häufiger auftaucht: Wie kann ich meine vorhandenen Business Intelligence Daten intelligent mit KI verknüpfen?
Die Antwort klingt einfacher, als sie ist. Denn während KI hervorragend mit unstrukturierten Texten umgehen kann, stellen strukturierte Datenbanken eine ganz eigene Herausforderung dar.
Das Problem: Strukturierte Daten treffen auf KI
Warum RAG nicht die Lösung ist
Der klassische RAG-Ansatz (Retrieval Augmented Generation) funktioniert brillant für Dokumente, PDFs oder Wissensdatenbanken. Dabei werden Texte in Vektoren umgewandelt und semantisch durchsucht.
Aber: BI-Daten in SQL-Datenbanken sind strukturiert. Sie leben von:
- Präzisen Aggregationen (SUM, AVG, COUNT)
- Komplexen JOINs über mehrere Tabellen
- WHERE-Bedingungen mit exakten Werten
- GROUP BY für Gruppierungen
Eine Vektor-Suche über Ihre Umsatztabelle wird niemals die Präzision einer SQL-Query erreichen. RAG ist hier schlicht das falsche Werkzeug.
Warum einfache SQL Tool Calls zu limitiert sind
Der nächste Gedanke: „Dann geben wir dem LLM einfach ein SQL-Tool!“
Das Problem dabei:
- Fehlende Kontextkontinuität: Bei jeder Frage muss das Modell den gesamten Schema-Kontext neu verstehen
- Keine Iteration: Komplexe Analysen erfordern mehrere aufeinander aufbauende Queries
- Reasoning-Overhead: Das konversationelle Modell muss gleichzeitig SQL schreiben UND clever antworten
- Prompt-Kollision: SQL-Syntax und natürliche Konversation kämpfen um Kontext-Space
Ein Modell, das beides können soll – SQL und Conversation – wird keines richtig gut machen.
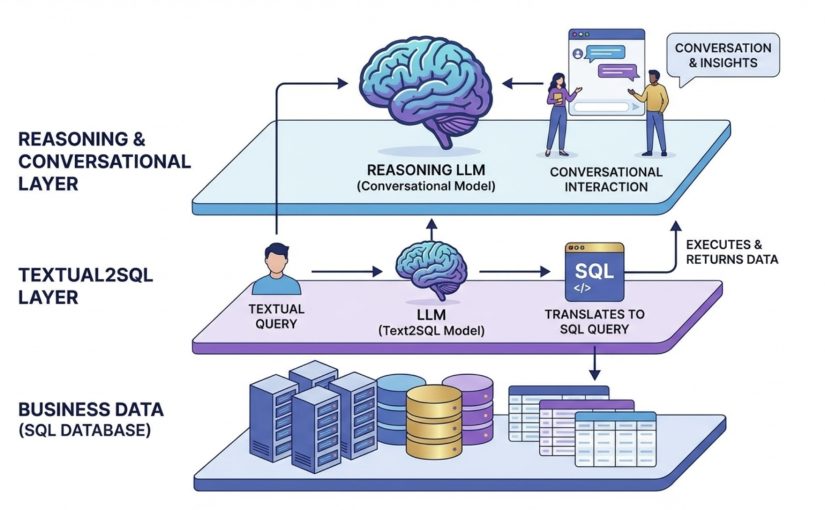
Die Lösung: Ein zweischichtiger Ansatz
Die elegante Lösung liegt in der Spezialisierung durch Layering. Statt ein Modell alles machen zu lassen, teilen wir die Arbeit auf zwei spezialisierte LLMs auf:
Layer 1: Text2SQL – Der Datenübersetzer
Das erste LLM hat eine einzige Aufgabe: Textuelle Anfragen in präzises SQL umwandeln.
Vorteile dieser Spezialisierung:
- Fokussiert nur auf Schema-Verständnis und SQL-Syntax
- Kann mit umfangreichem Datenbank-Kontext gefüttert werden
- Kein „Ablenkung“ durch Konversations-Anforderungen
- Kleineres, schnelleres Modell möglich (z.B. GPT-3.5, Claude Haiku)
Workflow:
- User fragt: „Wie viel Umsatz haben wir im Q4 gemacht?“
- Text2SQL-LLM übersetzt zu:
SELECT SUM(revenue) FROM sales WHERE quarter = 4 - Query wird ausgeführt, Daten kommen zurück
Layer 2: Reasoning LLM – Der Gesprächspartner
Das zweite, übergeordnete LLM ist Ihr intelligenter Analyst. Es:
- Führt die Konversation mit dem User
- Entscheidet, welche Daten benötigt werden
- Ruft das Text2SQL-LLM als Tool auf
- Interpretiert die Daten und zieht Schlussfolgerungen
- Stellt Nachfragen und führt Multi-Turn-Analysen durch
Beispiel-Dialog:
User: „Wie entwickelt sich unser Umsatz?“
Reasoning LLM denkt:
→ Brauche Umsatzdaten der letzten Quartale
→ Ruft Text2SQL auf: „Umsatz pro Quartal letzte 12 Monate“
→ Erhält Daten: Q1: 1.2M, Q2: 1.5M, Q3: 1.8M, Q4: 2.1MReasoning LLM antwortet:
„Ihr Umsatz zeigt einen deutlichen Aufwärtstrend mit +75% Wachstum über die letzten 4 Quartale. Besonders stark war Q4 mit +16% gegenüber Q3.“User: „Woran liegt das?“
Reasoning LLM denkt:
→ Brauche Breakdown nach Produktkategorie Q4
→ Ruft Text2SQL auf
→ Analysiert und antwortet: „Die Haupttreiber waren…“
Warum dieser Ansatz überlegen ist
1. Separation of Concerns
Jedes LLM macht, was es am besten kann:
- Text2SQL: Präzise SQL-Generierung
- Reasoning: Intelligente Analyse und Konversation
2. Bessere Performance
- Kleinere, schnellere Modelle für Text2SQL möglich
- Weniger Kontext-Switching
- Parallele Optimierung beider Layer
3. Höhere Qualität
- Text2SQL kann mit detailliertem Schema-Wissen trainiert werden
- Reasoning LLM konzentriert sich auf Insights, nicht auf Syntax
- Weniger „Prompt-Pollution“
4. Einfachere Wartung
- Schema-Änderungen? Nur Text2SQL anpassen
- Konversationsstil verbessern? Nur Reasoning-Prompts anpassen
- Klare Verantwortlichkeiten
5. Bessere Fehlerbehandlung
- SQL-Fehler können vom Text2SQL-Layer abgefangen werden
- Reasoning LLM kann alternative Fragen stellen
- Graceful Degradation möglich
Implementierung in der Praxis
Bei HybridAI setzen wir genau diesen Ansatz für unsere Kunden ein:
- Text2SQL-Layer: Ein spezialisiertes Modell, das mit Ihrem Datenbankschema vertraut gemacht wird
- Reasoning-Layer: Claude oder GPT-4 für natürliche Gespräche über Ihre Daten
- Sicherheit: Row-Level-Security und Zugriffskontrolle auf DB-Ebene
- Caching: Häufige Queries werden gecacht für schnellere Antworten
Das Ergebnis: Ihre Mitarbeiter können in natürlicher Sprache mit Ihren BI-Daten sprechen – präzise, schnell und intelligent.
Fazit
Die Verbindung von KI und strukturierten BI-Daten ist keine triviale Aufgabe. Weder RAG noch einfache SQL-Tools reichen aus.
Die Lösung liegt in der intelligenten Arbeitsteilung: Ein spezialisiertes Text2SQL-LLM übersetzt Anfragen in präzises SQL, während ein übergeordnetes Reasoning-LLM die Konversation führt und Insights generiert.
Dieser zweischichtige Ansatz vereint das Beste aus beiden Welten: Die Präzision strukturierter Queries mit der Flexibilität natürlicher Konversation.
Möchten Sie Ihre BI-Daten mit KI aufwerten? Bei HybridAI unterstützen wir Sie bei der Implementierung intelligenter Datenanalyse-Lösungen. Kontaktieren Sie uns für ein unverbindliches Gespräch.