Heute haben wir in der Prompt-Tuning-Clinic ein neues Feature gestartet – den Bereich „Evaluation Criteria“.
Eines der nervigsten Dinge im Umgang mit KI ist die ständige Suche nach der Antwort auf die Frage, ob eine individuell konfigurierte KI (Chatbot, Agent, Automation) eigentlich gut funktioniert oder nicht. In den meisten Fällen gehen sowohl Anbieter als auch Kunden so damit um:
„Gestern habe ich diesen Prompt laufen lassen, sah ziemlich gut aus, guter Fortschritt!“
– oder –
„Mein Chef hat sie gebeten, X zu machen, und sie hat eine komplett falsche Antwort geliefert – wir müssen alles neu machen!“
Das ist bis zu einem gewissen Grad ein inhärentes Problem von KI: zum einen wegen der universellen Einsatzmöglichkeiten dieser Systeme und der Tatsache, dass man praktisch alles fragen kann und immer eine Antwort bekommt. Und zum anderen, weil es aufgrund der nicht-deterministischen Architektur und Funktionsweise dieser Systeme sehr schwer ist, klar zu definieren, was sie können und was nicht.
Wir waren davon etwas genervt und haben uns gefragt: Warum lesen wir alle paar Tage LLMarena (btw wir haben kürzlich die „German LLM-Arena“ gestartet, bitte hier ausprobieren) und andere Rankings neuer KI-Modelle – wenden aber ähnliche Mechanismen nicht auf die Installationen unserer Kunden an?
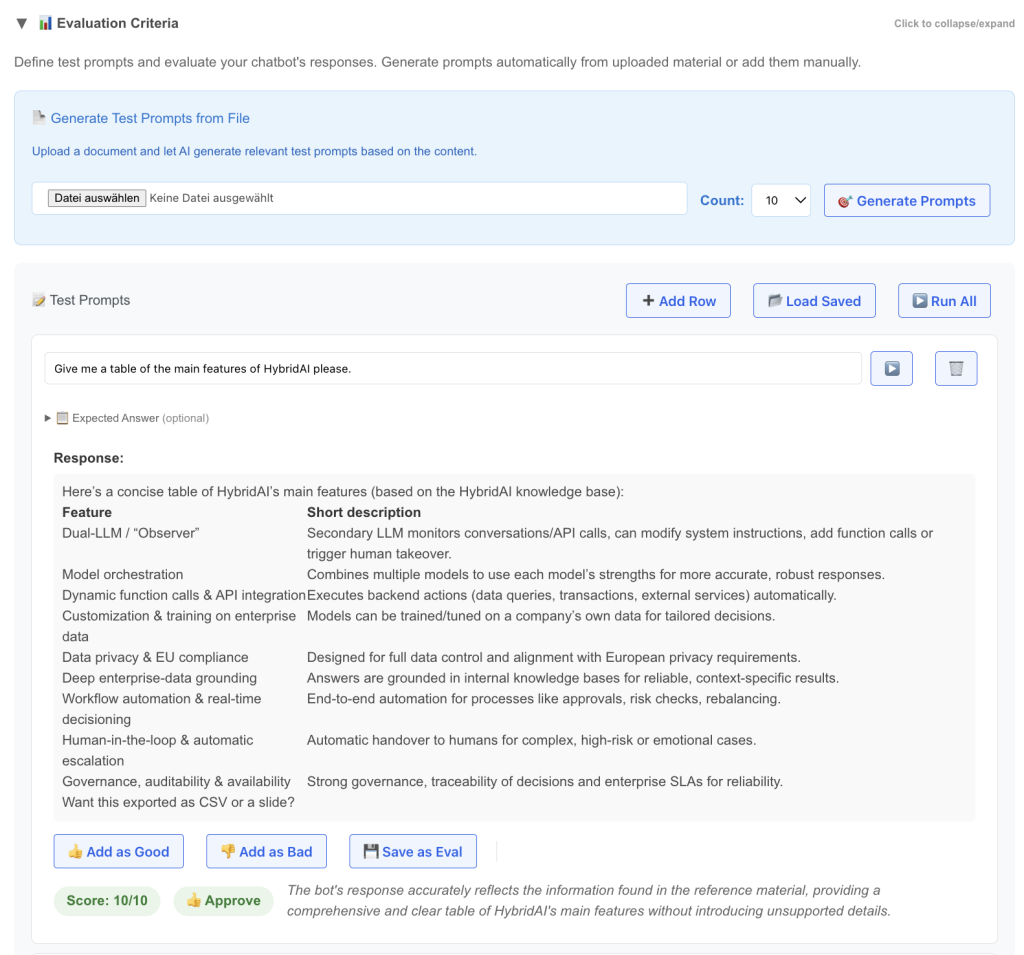
Genau das bringt dieses neue Feature:
- Definiere eine Reihe von Test-Prompts (du kannst z. B. Behandlungsmaterial wie API-Dokumentationen oder eine Markdown-Datei der Website hochladen und die KI Test-Prompts vorschlagen lassen)
- Führe diese Prompts gegen die aktuelle Konfiguration des Bots aus
- Bewerte die Antworten (das kann auch automatisch durch ein LLM erfolgen)
- Definiere korrekte Antworten für Edge Cases
- Speichere wichtige Prompts dauerhaft
- Vergib Daumen hoch / runter, um Fälle für Fine-Tuning und DSPy zu erzeugen
- Führe alle Tests aus, um ein Qualitätsranking zu erhalten
Sobald das einmal eingerichtet ist, ändert sich das Spiel grundlegend, denn jetzt haben wir (sowohl Anbieter als auch Kunde) ein klar definiertes Test-Set für das gewünschte Verhalten, das automatisch ausgeführt werden kann.
Das ist nicht nur für das initiale Setup eines Systems hilfreich, sondern auch für Verbesserungen, Modell-Updates, neue Einstellungen usw.
Und: Da wir auch Fine-Tuning für unsere Modelle anbieten und DSPy als automatisiertes Prompt-Tuning-Tool integriert haben, kannst du beim Erstellen deines Evaluations-Sets gleichzeitig Trainingsdaten erzeugen. Ein einfacher Daumen hoch / runter auf eine Antwort erzeugt automatisch einen Eintrag in der Test-Datenbank für später.
Melde dich für einen kostenlosen Account an und probiere es aus!