Schneller, günstiger, kontrollierbarer – und trotzdem leistungsstark: Small Language Models erobern den Enterprise-Bereich.
Während die Welt auf GPT-5, Gemini 3 und immer größere Modelle schaut, passiert im Hintergrund etwas Spannendes: Kleine Sprachmodelle (SLMs) entwickeln sich rasant weiter und werden zur echten Alternative für Unternehmensanwendungen. In unserem aktuellen Webinar haben wir gezeigt, warum das so ist – und unsere eigenen feingetunten Modelle live demonstriert.
Das Problem mit den Großen
80-95% aller Corporate-KI-Projekte scheitern. Eine ernüchternde Zahl, die durch die Tech-Presse geistert. Aber warum?
Ein Hauptgrund: Die großen Sprachmodelle wie ChatGPT oder Claude sind für den Enterprise-Einsatz oft problematisch. OpenAI hat kürzlich beim Release von GPT-5 einfach mal die alten Modellvarianten vorübergehend abgeschaltet – ein Albtraum für jede Corporate-IT mit laufenden Prozessen. Dazu kommen Datenschutzbedenken, unvorhersehbares Verhalten und die Abhängigkeit von amerikanischen Cloud-Diensten.
Klein, aber oho: Die Vorteile von SLMs
Small Language Models (typischerweise zwischen unter 1 bis 20 Milliarden Parameter) bieten handfeste Vorteile:
⚡ Geschwindigkeit: Antworten im Millisekundenbereich statt Sekundenlanger Wartezeiten. Wer einmal die Responsivität eines lokalen SLMs erlebt hat, will nicht mehr zurück.
🔒 Datenschutz: Läuft auf eigenen Servern, braucht kein Internet, keine Daten verlassen das Haus. Ideal für sensible Unternehmensdaten.
🎯 Kontrolle: Keine überraschenden Modell-Updates, keine plötzlichen Verhaltensänderungen. Das Modell macht genau das, was es soll.
💰 Kosten: Deutlich günstiger im Betrieb als API-Calls zu den großen Anbietern.
🔧 Anpassbarkeit: Durch Finetuning lassen sich SLMs präzise auf spezifische Aufgaben trainieren – und zwar mit überschaubarem Aufwand.
Das Geheimnis: LoRA-Finetuning
Der Game-Changer heißt LoRA (Low-Rank Adaptation). Diese Technik ermöglicht es, Modelle mit erstaunlich wenig Daten (ab ~100 Beispielen) und Rechenpower anzupassen. Das Prinzip: Man trainiert nur einen kleinen „Adapter“, der über die Modellgewichte gelegt wird – keine Neutrainierung des gesamten Modells nötig.
Das Ergebnis? Ein Modell, das nicht nur die richtigen Antworten gibt, sondern auch im richtigen Stil antwortet. Wer jemals versucht hat, ChatGPT per Prompt dazu zu bringen, kürzere Antworten zu geben oder bestimmte Formatierungen zu vermeiden, weiß wie schwierig das ist. Mit Finetuning funktioniert es zuverlässig.
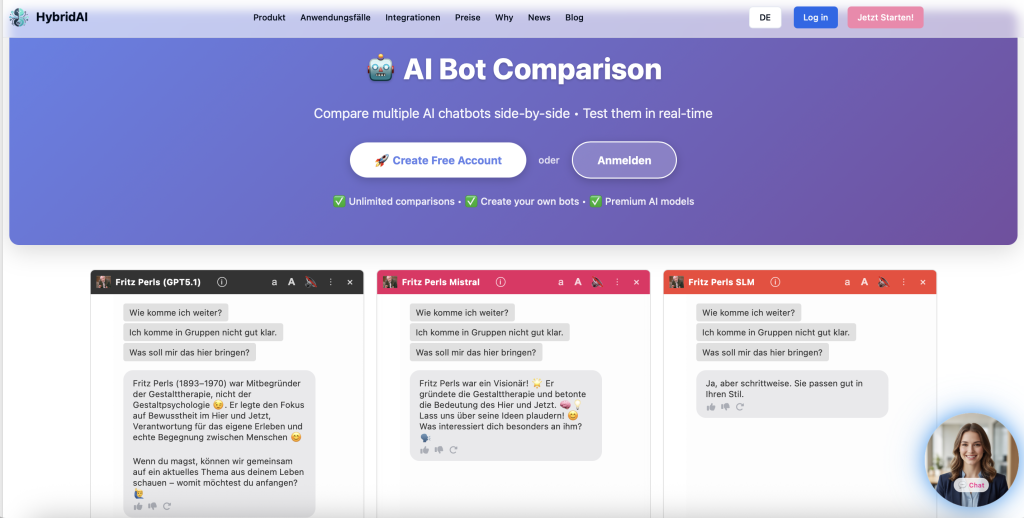
Live-Demo: Unsere eigenen SLMs
Im Webinar haben wir drei feingetunte Modelle gezeigt, alle basierend auf dem LFM-2 von LiquidAI mit nur 1,2 Milliarden Parametern:
- Allgemeines Deutsch-Modell: Solide Antworten zu alltäglichen und fachlichen Fragen
- Fritz Perls Therapie-Bot: Ein Modell, das den konfrontativen Gesprächsstil des Gestalt-Therapeuten Fritz Perls perfekt imitiert
- Marktforschungs-Assoziationsmodell: Analysiert implizite Markenassoziationen im Stil professioneller Marktforschung
Die Responsivität ist beeindruckend – die Antworten kommen praktisch sofort. Und das Beste: Alles läuft auf unseren eigenen europäischen Servern.
Die Zukunft: Hybrid ist King
Unsere Vision bei HybridAI: Die Kombination macht’s. Kleine, feingetunte Modelle für die Routine-Aufgaben, große Modelle für komplexe Anfragen – orchestriert durch eine intelligente Steuerungsschicht, die erkennt, welches Modell gerade das richtige ist.
Das gibt Unternehmen das Beste aus beiden Welten: Schnelle, kontrollierbare, datenschutzkonforme Antworten für 80% der Anfragen – und die Power der großen Modelle, wenn es wirklich nötig ist.
Selbst ausprobieren?
Wir stellen unsere SLM-Demo öffentlich zur Verfügung (hier geht’s zur Live-Demo). Testet selbst, wie sich die kleinen Modelle schlagen – und kontaktiert uns, wenn ihr über eigene feingetunte Modelle für eure Anwendungsfälle sprechen wollt.